CNN(Convolution Neural Network)이란? - 개념과 특징
안녕하세요. 제가 진행 중인 프로젝트에서 딥러닝 모델 중 가장 높은 성능을 낸 CNN은 어떤 모델인지 다뤄볼까 합니다. CNN은 어떤 모델이길래 데이터셋이 작은 환경에서도 다른 모델에 비해 뛰어난 성능을 낼 수 있는지 알아보겠습니다.
CNN은 특히 이미지 인식에 많이 사용되는 딥 러닝 모델입니다.
개요
입력된 값에서 특징을 추출하여 패턴을 파악하여 다음 값을 예측하는 게 딥러닝과 머신러닝의 특징입니다. 적절한 특징을 추출하기 위해서 학습 과정에서 변수를 조절하며 어떤 값으로 변수를 설정해야 원하는 값이 나오는지 알아내는 거죠.
CNN의 filter
CNN의 filter를 설명하는 다양한 방법 중 저는 혼자 공부하는 머신러닝+딥러닝(박해선 저) 에서 설명했던 도장 이라는 설명이 제일 와 닿았습니다. 이해한만큼 설명해보겠습니다.
- filter라는 도장이 있습니다. 이 도장은
kernel_size라는 변수에 지정된 값의 크기를 갖습니다.(주로 2 x 2, 혹은 3 x 3을 많이 사용한다고 합니다. ) - 도장에는 도장을 찍는 부분 중 특정한 값이 돋보이게 하도록 하는 기능이 있습니다.(도장에 가중치가 정해져 있어 도장을 데이터 찍으면 가중치에 따라 그 값을 더 크게 하거나 더 작게 하는 형식으로 강조할 데이터를 정합니다.)
- 도장이 찍혀 나온 값(가중치가 곱해진 값)을 다 더해 도장의 결과물을 만듭니다.
- 이 행위를 데이터 전체에 행합니다.
- 결과물들을 모은 데이터를 컨볼루션 이라고 부르고 이 데이터를 차곡차곡 쌓습니다. 도장 당 컨볼루션이 하나씩 나오는 거죠.
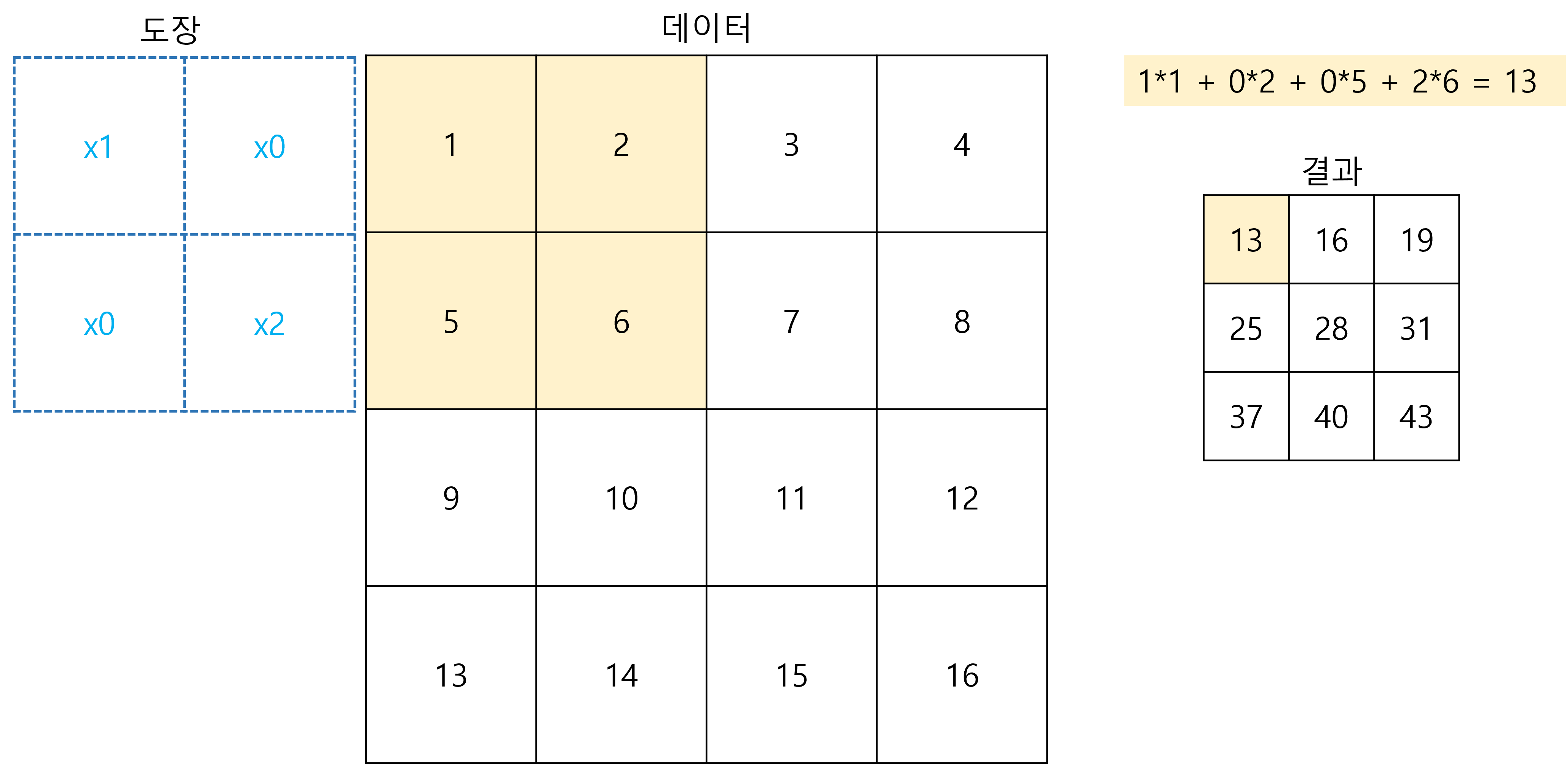
첫 번째 도장 찍기
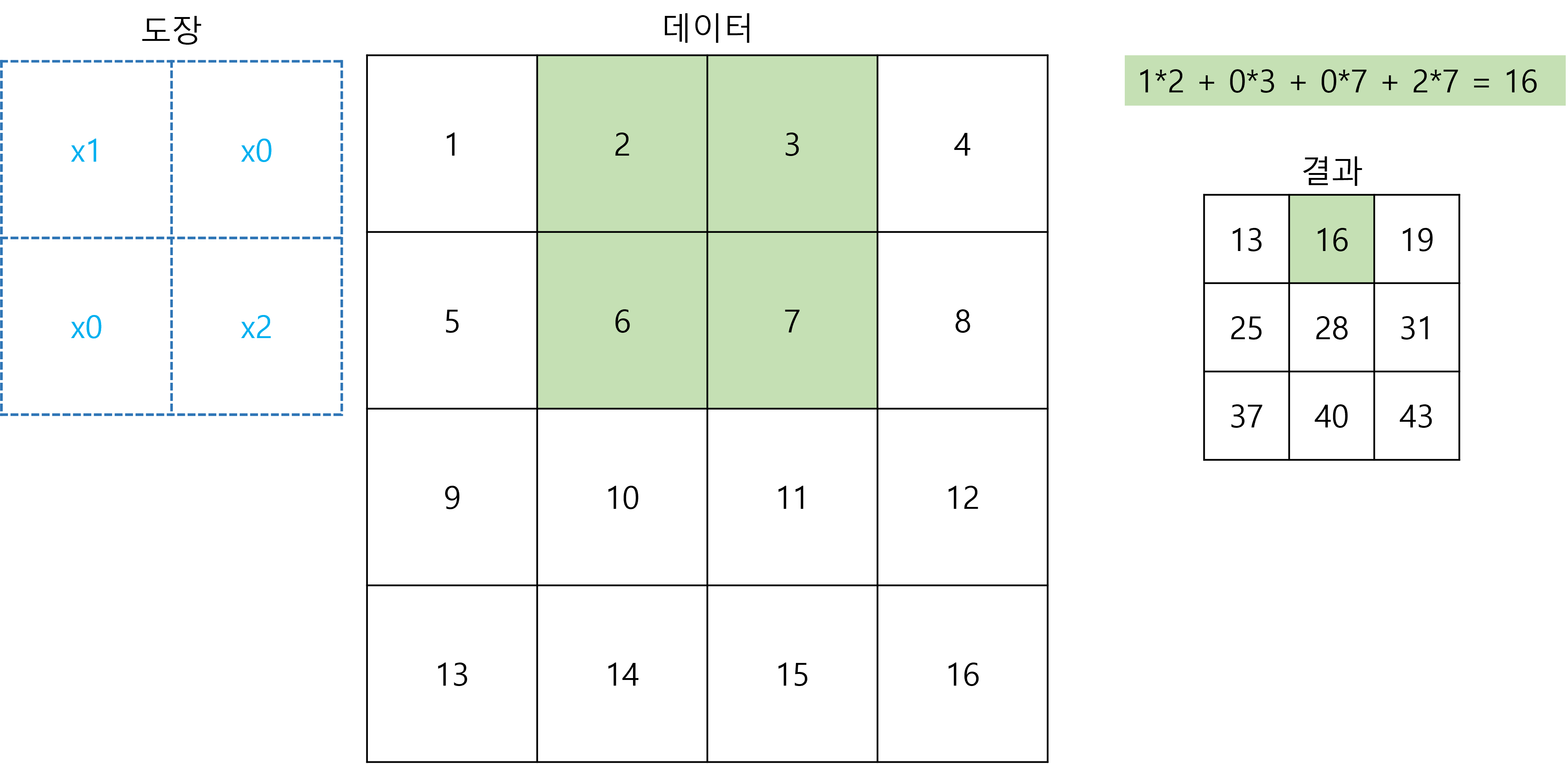
도장을 옆으로 옮겨서(stride 1일 때) 찍기
그림처럼 옆으로 한 칸씩 옮길 수도 있고 stride에 정해진 값 만큼 건너뛰어서 도장을 찍을 수도 있습니다. 그러나 stride를 사용하면 사용하지 않는 데이터가 있기 때문에 stride를 1로 한 후 Pooling을 통해 크기를 줄이는 것보다 정확도가 떨어집니다.
Padding
위 예제에서 볼 수 있듯이 컨볼루션은 입력 데이터보다 크기가 작아집니다. 또한 모서리나 테두리 부분이 가장자리 부분보다 도장이 적게 찍히는 현상이 발생합니다. 이를 방지하기 위해서 데이터 주변에 0을 채우는 방식의 same padding 을 주로 사용합니다. 데이터 주변에 0을 채워 모든 데이터가 비슷한 횟수로 도장이 찍히도록 만드는 거죠. 대신 0으로 채웠기 때문에 결과에 영향을 주진 않습니다. 또한 same padding을 사용하면 컨볼루션의 크기가 입력 데이터와 동일하게 됩니다.
Pooling
데이터가 너무 크고 주위에 비슷한 값이 있어 모두 가지고 가는 것보다 대푯값을 이용하는 게 더 효과적일 수도 있습니다. 이럴 때는 Pooling을 사용합니다.
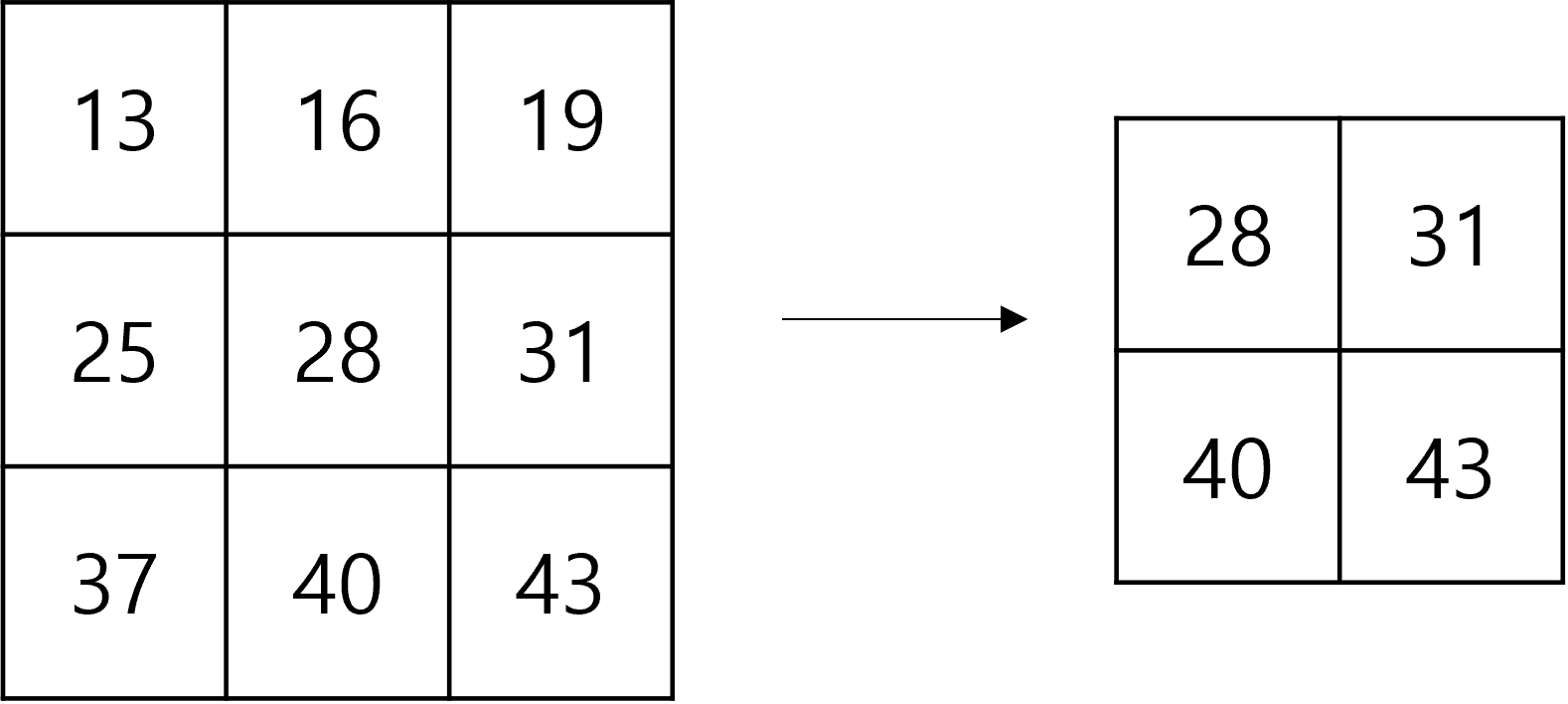
pooling size = 2 일 때
- Pooling은 Average Pooling, Max Pooling 등이 있습니다. 책에서는 Average보다는 Max를 보편적으로 더 많이 사용한다고 했는데 이유는 Average를 사용하면 돋보이는 값이 희석되어 효과가 반감되기 때문이라고 합니다.
- Max Pooling은 가중치가 없는 도장과 비슷하다고 생각하시면 됩니다. 따라서 Max pooling에서도 도장의 크기를 정해야 합니다. (예시에서는 2로 정했습니다.)
- 예시에서 첫 번째 칸에 max pooling을 진행하면 13, 16, 25, 28중 가장 큰 값인 28이 선택됩니다.
CNN 전체 구조

출처: https://youtu.be/tPLRox0YYc8
저자 분께서 유튜브 강의를 진행하신 내용 중 일부를 캡쳐해왔습니다.
정리해보자면
- 입력된 4x 4 데이터에 패딩을 적용해 가장자리에 0인 셀을 추가합니다.
- 도장 3개를 찍어서 도장마다 컨볼루션을 만들어 총 3개의 컨볼루션이 만들어졌습니다.
- 컨볼루션의 크기를 줄이기 위해 Max Pooling을 진행합니다. 이 때 pooling size는 2로 만들었기 때문에 결과물은 컨볼루션의 반인 2x2 가 됩니다.
- 밀집층에 결과를 넣기 위해서는 3차원 데이터를 1차원으로 펼쳐야 하기 때문에 flatten 기능을 사용하여 2x2x3으로 이뤄졌던 데이터를 1차원으로 펼칩니다.
- 펼친 데이터를 출력층에 넣습니다.
CNN 특징
- 필터(도장)을 여러 개 적용함으로써 데이터에 있는 다양한 특성을 각각 학습 가능합니다.
- 사람이 직접 특징을 추출할 필요 없이 데이터가 주어진다면 모델이 직접 학습합니다.
- 제 추측이지만 프로젝트에서 사용하는 데이터셋은 센서 데이터로 이뤄져 있고 산업 환경에서 사용되는 것을 가정으로 하기 때문에 값이 거의 변하지 않는 경우가 대부분입니다. 그 중 가끔 특이한 값이 있고 이를 통해서 오류를 예측하는 거죠. 이런 경우 모든 데이터를 다 사용하기 보다 CNN처럼 필터와 Max Pooling을 통해 비슷한 데이터 중 조금 다른 데이터에 가중치를 많이 주게 되어 극대화함으로써 약간의 변화를 두드러지게 보이는 것이 다른 신경망 모델보다 좋은 성능을 내게 하는 요인이 아닐까 합니다.
참고
- 혼자 공부하는 머신러닝 + 딥러닝 이해가 쉬운 그림과 설명이 좋았고 구글 코랩을 통해 힘든 개발환경 구축 없이 예제를 따라해볼 수 있어서 정말 좋았습니다. 처음 시작하는 사람에게도 상세한 설명과 와닿는 비유로 이해가 쉬워서 처음 시작하는 저 같은 분에게 추천드리고 싶습니다.
댓글남기기