RNN(Recursive Neural Network)란? - 개념과 특징
순차 데이터
보통의 모델들은 현재 층의 출력이 다음 층으로 전해집니다. 그러나 이 같은 경우 이번 데이터와 이전 데이터 간의 관계는 무시됩니다. 예를 들어 수 많은 와인의 특징을 담은 데이터의 경우 와인 데이터 간의 관계는 없습니다. (와인1 옆에 있던 와인2가 와인1 옆에 있었다는 이유 만으로 와인1의 영향을 받아 특성이 결정되는 경우는 없다는 뜻입니다. 물론 지리적으로 가까이 위치했다는 것은 생산된 날짜 등의 특징이 비슷하기 때문 일거란 가정을 할 수는 있습니다만 여기서는 이런 경우를 제외합니다.) 와인 데이터의 순서를 섞어도 아무런 상관이 없죠.
그러나 모든 데이터가 그런 것은 아닙니다. 단어의 경우 ‘저는 망고를 좋아합니다.’를 ‘망고를 좋아합니다. 저는’ 로 순서를 섞는다면 의미를 파악하기 힘듭니다. 이렇게 순서가 상관 있는 데이터를 순차 데이터라고 합니다. 언어, 시간 별로 측정된 실내 온도 등이 대표적이죠. 제가 프로젝트에서 다루고 있는 센서 데이터도 시간 별로 나열된 데이터 시계열 데이터 입니다.
RNN의 필요성
이런 데이터는 1 다음에 2가 오는 순서가 중요합니다. ‘저는’ 다음 ‘망고를’이 오는 것처럼요. 이렇게 순서를 고려하기 위해서는 결과적으로 이전 출력을 기억하고 활용해야 합니다. 사람도 ‘저는’이라는 단어가 먼저 왔다는 기억하고 문장을 해석하는 것처럼요. 그러나 이전 모델은 앞에서 얘기했던 것처럼 출력이 다음 층으로만 전해집니다. 즉 기억을 하지 못하는 거죠. 이를 해결하기 위해 RNN이 등장합니다.
RNN이란
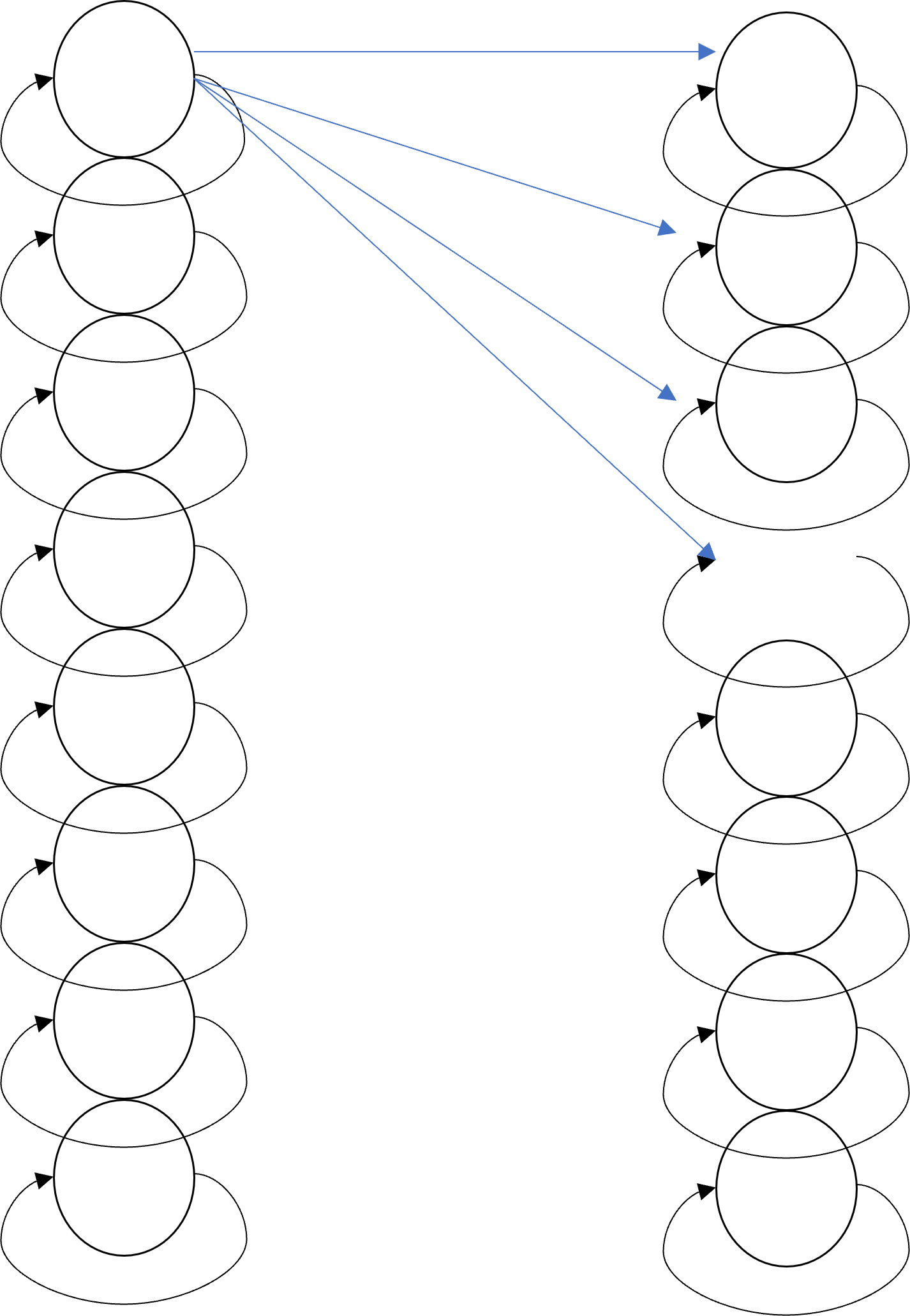
RNN의 신경망
이전 데이터의 출력을 이번 데이터를 분석하는데 다시 사용하기 위해서 RNN은 Recursive 특성을 가지게 됩니다. 즉 출력을 다시 입력으로 입력 받는 거죠.
위 그림에서 볼 수 있듯이 셀의 출력이 다시 셀의 입력으로 들어가는 것을 확인할 수 있습니다. 물론 이 출력은 다음 층으로도 이어집니다. 파란색 화살표를 4개 밖에 그리지 않았지만 모든 셀이 다음 층의 모든 셀에 연결되어 있는 아주 복잡한 모양이죠.
이 셀들은 가중치를 조절하며 학습을 반복하게 됩니다.
RNN 한계 및 보안 모델
- RNN은 현재 셀의 출력을 다시 입력으로 사용합니다. 그러나 이렇게 하면 다음 데이터를 받을 수록 이전 데이터에 대한 기억은 희미해지고 결국 효과가 없어집니다. 즉 몇 단계 전에 있는 데이터는 반영하기 힘들어집니다.
- 이를 해결하기 위해 Long Short Term Memory, LSTM이 등장합니다. LSTM은 셀의 내부를 더욱 복잡하게 만들어서 저장할 데이터와 저장하지 않을 데이터를 분리합니다.
LSTM
- LSTM은 RNN과 달리 다음 층으로 전달되지 않고 현재 층으로 되돌아가기만 하는 출력이 따로 존재합니다. 이 값을
cell state라고 부릅니다.- 입력과 은닉상태를 가중치에 곱한 후 시그모이드를 통과합니다.
- 이전 타임 스텝의 셀 상태와 곱해 새로운 셀 상태를 만듭니다.
- 이 새로운 셀 상태는 tanh 함수를 통과하여 새로운 은닉 상태를 만드는데 기여합니다.
- LSTM 셀 내에는 삭제 게이트, 입력 게이트, 출력 게이트가 존재합니다. 삭제 게이트에서는 무엇을 삭제할 지 정하고 입력 게이트에서는 입력값을 조절하여 cell state를 결정합니다. 출력 게이트에서는 cell state의 값과 입력을 이용하여 해당 셀의 출력을 만듭니다.
- LSTM의 셀 내에는 이를 구현하기 위해 조그만 셀이 4개 들어 있습니다.
- LSTM을 여러 층으로 쌓기 위해서는 출력 층에서만 은닉층만을 출력으로 내놓고 이전 층에서는 모든 순환층을 다 전달해야 합니다.
GRU
- LSTM으로 긴 시퀀스를 처리할 수 있게 되었지만 연산이 많은 단점이 있습니다. 따라서 LSTM의 간소한 버전으로 GRU가 등장합니다.
- GRU의 경우 셀 내 조그만 셀이 3개 들어 있습니다.
- 삭제 게이트, 입력 게이트, 출력 게이트는 존재하지만 cell state는 없습니다.
참고
- 혼자 공부하는 머신러닝 + 딥러닝(박해선 저)
댓글남기기