Hierarchical Temporal Momory (HTM, 계층형 시간 메모리)란?
안녕하세요. 요즘 딥러닝과 머신러닝을 공부하고 있는데 공부한 내용을 정리해놓으면 좋을 것 같다는 생각이 들어서 첫 게시글을 작성하게 되었습니다.
(참고로 이 게시글을 작성할 때는 이미 기본적인 딥러닝과 머신러닝 개념을 공부한 상태여서 간단한 용어 정도는 알아들을 수 있는 정도였고 그 기준으로 게시글을 작성할 예정입니다. 어쨌든 제가 나중에 보기 위해 기록하는 목적이니까요)
오개념이 있다면 언제든지 댓글을 통해 알려주시기 바랍니다^^
특징
Numenta 라는 회사에서 제안한 framework로 RNN과 자주 비교됩니다. RNN처럼 Sequential data를 다루는 데 적합하기 때문입니다.
Numenta 홈페이지에 어떤 분이 정리해주신 걸 토대로 HTM과 RNN의 차이를 정리해보자면
- HTM에 RNN 보다 복잡한 뉴런 모델을 가지고 있습니다.
- HTM은 back propagation을 하지 않고 unsupervised hebbian-learning rule 만을 이용합니다.
back propagation(오차 역전파)이란?
loss function의 값을 기준으로 loss가 최솟값을 가질 수 있도록 모델의 weight(가중치)를 조절하는 것입니다. 이 때 최종 결과를 내는 layer와 가장 가까운 쪽부터 weight를 조절하며 input layer까지 weight를 조절하게 되므로 back propagation이라고 부릅니다.
Hebbian Theory
반복적으로 함께 활성화되는 cell들끼리 연관이 있다고 판단하여 연관 있다고 판단한 cell을 연결합니다. 연결된 cell 중 일부가 활성화되었다면 연결되어 있는 다른 cell 또한 활성화될 것이라고 판단하고 활성화시킵니다.
- HTM은 activation과 뉴런 연결이 분산되어 있습니다.
(_sparse_라고 원문에서는 표현했는데 규칙적으로 activation cell이 위치하지 않고 cell 간의 연결 또한 규칙적이지 않다는 뜻으로 해석했습니다.) - HTM은 이진 units과 weights를 가집니다.
이런 HTM은 다음과 같은 상황에 특히 좋은 성과를 냅니다.
- Sequential data 를 다룰 때
- Contextual meaning이 있는 데이터를 다룰 때
- I am a boy/I am a girl 과 같이 ‘I am a’까지는 동일하지만 이후에 오는 데이터가 다를 때
- 모델이 지속적으로 새로운 데이터를 학습해야 할 때
- noise가 많은 데이터를 다룰 때
- Hyperparpameter를 tuning 하기 힘들 때
이 중 특히 4 ~ 6번은 RNN 및 RNN에서 파생된 LSTM, GRU를 이용해서는 해결하기 힘든 문제들입니다.
이 후 내용은 Numenta에서 운영하고 있는 유튜브 채널에서 매우 상세히 설명해 놓은 걸 제 나름대로 해석한 것입니다. 원본 영상 링크는 글 끝에 남기겠습니다.
원리
SDR (Sparse Distribute Representation)
0과 1로 이뤄진 array로 activate 된 bit는 1 나머지는 0으로 표현하는 방식입니다. 이 방식은 사람의 두뇌 속 뉴런이 상황에 따라 일부만 활성화되고 나머지는 비활성화 상태인 것을 컴퓨터적으로 표현하여 사용하는 방식이라고 합니다.
SDR의 장점은 두 데이터 간 비교가 쉽고 빠르다는 것입니다.(이건 제 생각이지만 컴퓨터에서 bitwise and와 or를 처리하는 속도가 매우 빠르므로 SDR이 이러한 장점을 갖는 것이 아닐까 합니다.) 자세히 보자면, 두 데이터를 AND 하여 overlap score(1인 부분이 겹치는 개수)를 계산하기 쉽습니다. 또는 두 데이터를 OR하여 두 가지 경우에 대한 확률을 모두 나타낼 수도 있습니다.
AND
x = 0100 0111, y = 1000 0110 의 경우 x AND y = 0000 0110 으로 overlap score는 2라고 할 수 있습니다.
만약 두 데이터가 동일하다고 판단하게 되는 임계점인 threshold가 2라면 두 데이터는 같은 데이터라고 판단하게 됩니다. threshold가 3이라면 두 데이터는 다른 데이터라고 판단합니다.이렇게 구한 overlap score를 통해 nosie가 어느 정도 있는지, 어디에 있는지 또한 확인이 가능합니다. 예로 x가 원본데이터, y가 noise가 가미된 데이터라고 하면 원본 데이터에는 1인 부분이 4개인데 반해 AND operation을 진행한 결과에는 1이 2개이므로 1인 부분에는 noise가 없지만 다른 부분에는 noise가 발생했다는 것을 확인할 수 있고 50%(4개 중 2개이므로) 정도 noise가 있다고 판단할 수 있게 되는 것입니다.
OR
위와 똑같이 x = 0100 0111, y = 1000 0110 의 경우 x OR y = 1100 0111입니다. 계산의 결과로 나타난 1100 0111은 이 데이터가 x일 확률과 y일 확률을 모두 고려하고 있다고 볼 수 있습니다. 이는 HTM에서 일부 sequece는 동일하지만 이후 데이터가 다른 경우 결과(위의 예에서 I am a boy/girl과 같은)를 예측하는데 사용됩니다.
HTM은 특히 noise tolerance가 뛰어납니다. 영상에서 들었던 예시로는 원본 데이터에 noise가 30% 정도 있을 때 false positive(아닌 걸 맞다고 판단하는 경우, 예를 들어 실제로는 코로나 확진자가 아닌데 코로나 확진자라고 판단하는 경우) 가능성이 10의 -51 제곱 정도로 매우 작다고 합니다.
참고로 HTM에서 최소로 요구하는 SDR array length = 2048, population은 40입니다.
Temporal Memory
HTM은 column 내에 여러 개의 cell이 들어있고 이러한 column이 여러 개 모여 있는 형식입니다.
Proximal input
Proximal input은 column 내에 여러 cell이 SDR data와 연결하여 data를 읽어오는 것입니다. 밑의 그림을 보시면 이해가 쉬우실 것 같습니다.
노란색이 column, 검은 동그라미가 column안에 들어있는 cell입니다. 초록색은 SDR encoding된 데이터이고 파란색 선들이 SDR data를 읽어오고 있는 cell의 연결이라고 보시면 됩니다. 이 연결을 proximal이라고 합니다.
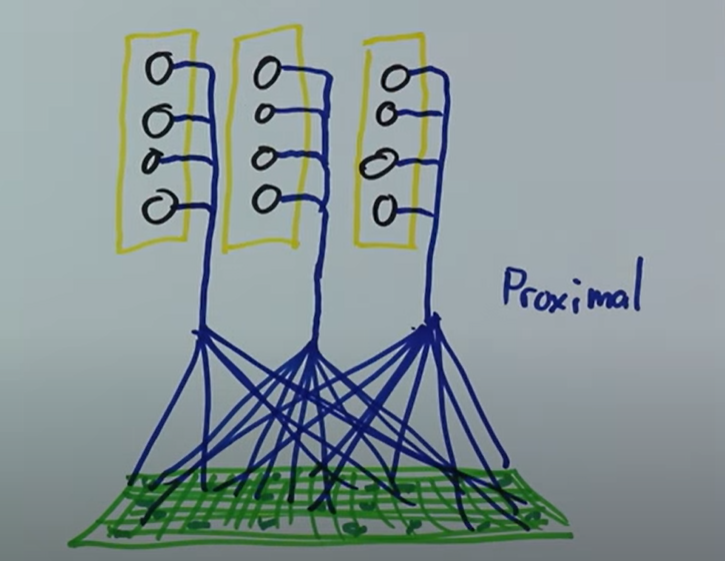
출처: https://www.youtube.com/watch?v=UBzemKcUoOk
Distal
Distal은 cell끼리의 연결을 말합니다. 이 연결에 의해 다음 phase에 active될 cell을 예측할 수 있게 되고 이렇게 예측한 cell을 predictive cell이라고 부릅니다. 현재 활성화된 cell이 모두 연결된 cell이 predictive cell이 됩니다.
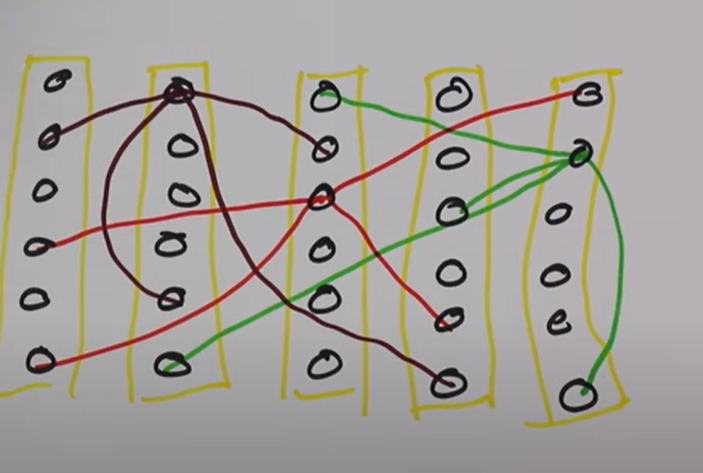
출처: https://www.youtube.com/watch?v=UBzemKcUoOk
예시
영상에서 설명했던 예시를 그대로 설명해보겠습니다.
F E C A 순서로 악기를 연주하고 있다고 가정해보겠습니다.
- 첫 번째로 이 순서를 접할 때는 아무것도 모르고 있는 상태이므로 모든 activation column에 있는 cell이 활성화됩니다. 이를 bursting이라고 부릅니다. 또한 이 때는 결과값으로 어떠한 예측도 내놓지 않습니다. 처음 배우는 것이니까요!
- 두 번째로 이 순서를 접할 때는 조금 다릅니다.
1) F를 접할 때는 이전에 주어진 어떠한 음도 없기 때문에 아무것도 예측하지 못합니다. 따라서 여전히 activation column의 모든 cell이 활성화되는 bursting이 일어납니다.
2) 첫 번째로 음의 순서를 접하면서 모델은 F 다음에 E C A가 온다는 것을 학습했습니다. 따라서 현재 음이 F이므로 다음이 E라는 것을 예측합니다. 정확히는 F에 해당하는 cell이 모두 연결된 predictive cell들을 활성화시킵니다. 이 cell들은 E를 나타내고 predictive cell이 포함되어 있는 column이 active column이 됩니다.
3) 2)와 같은 원리가 C와 A에도 적용됩니다. - 2번과 같은 순서로 계속 진행되면서 모델은 학습한 결과인 feedforward input 뿐 아니라 혹시 새로운 패턴이 들어오지는 않는지 확인할 수 있도록 distal input도 계속 체크합니다. 즉 앞에서 얘기했던 대로 지속적으로 새로운 데이터를 학습할 수 있습니다!
이 때 만약 음의 순서가 변경된다면 어떻게 될까요?
이번에는 위에서처럼 F E C A를 학습한 모델에게 어느 순간 F C F A라는 음이 들어왔습니다.
- 모델은 하던대로 F C를 지나옵니다. 그런데 이번에는 E가 아니라 F가 들어와 있습니다.
(이 때 첫번째 F와 두 번째 F는 다른 F라고 판단합니다. 첫번째 F는 context 상 처음에 위치하고 두 번째 F는 context 상 E 다음에 위치하니까 다른 F라고 판단하는 거죠. 즉 HTM은 sequential data, context data를 이해할 수 있습니다.) - 모델은 F C F A라는 새로운 패턴을 학습하기 위해 bursting 합니다.
- 결과적으로 F C 다음에는 predictive cell이 2배가 됩니다. 하나는 E를 예측하는 predictive cell, 다른 하나는 F를 예측하는 predictive cell입니다. (이 때 위에서 배운 SDR 데이터를 OR operation하면 빠르게 처리가 가능하겠죠?) 따라서 50%의 확률로 E 혹은 F를 예측하게 됩니다.
이렇게 새로운 패턴을 배울 때마다 HTM의 predictive cell은 늘어납니다. 그리고 등장한지 오래된 패턴에 대한 predictive cell은 잊어버리게 되죠.
여기서 column당 여러 cell이 predictive cell이 될 수 있다고 했는데 이런 방식을 High Order Sequence Memory 방식이라고 합니다. 반면에 column당 하나의 cell만 predictive cell이 될 수 있다면 Single Order Memory입니다. Single Order Memory의 경우 1 2 3 4 5 라는 데이터는 잘 이해할 수 있지만 1 2 3 4 5 4 3 2 1과 같은 데이터는 2 후에 3 혹은 1이 오기 때문에 예측하지 못합니다.(3을 나타내는 predictive cell 혹은 1을 나타내는 predictive cell 하나만 나타낼 수 있기 때문)
정리
이러한 방식을 통해서 HTM은 sequential, context data를 효과적으로 처리(F C F A, F C E A 분석 가능)할 수 있고 동시에 여러 결과값을 예측할 수 있으며(E 혹은 F) 새로운 패턴을 지속적으로 배울 수(feedforward data, distal data 모두 확인) 있습니다. 또한 SDR을 사용하여 noise에 강하고 feedforward 방식을 사용하여 하이퍼파라미터 튜닝을 할 필요가 없습니다.
참고
더 자세히 알고 싶으시다면 제가 참고한 사이트를 방문해보시면 좋을 것 같습니다. 자료가 영어지만 이 글을 큰 틀로 잡고 이해하시면 무리가 없으실 것 같습니다.
- HTM의 특징을 Numenta blog를 통해 RNN과 비교하며 설명합니다.
- SDR과 사람 두뇌간의 연관, 왜 SDR은 noise에 강한지 등에 대해 효과적인 시각자료와 함께 설명합니다.
- 위에서 들었던 F C F A 예제를 activation column과 cell을 효과적으로 나타낸 시각자료와 함께 설명합니다.
- HTM 개념에 대한 간결한 설명과 위에서 들었던 1 2 3 4 5 4 3 2 1 예제를 htm.core를 이용하여 파이썬 코드와 함께 차근차근 설명합니다.
#이 글이 도움이 되었다면 댓글로 알려주세요^^
댓글남기기